

新闻资讯
实时关注我们,我们与世界时刻再变动

很长一段时间,CPU 主导了整个数据中心,虚拟化算力成为云计算的重点。
直到人工智能应用的爆发性增长,GPU 的芯片架构被发现更适合支持大规模的AI模型训练和推理,GPU 成为数据中心第二大算力芯片。
当数据中心基础设施遇到的瓶颈越来越难以克服时,新一代 DPU 出现了。
01DPU是什么?
DPU是面向基础设施层的数据处理单元。所谓的基础设施层,是有别于应用层而言的、为了给“应用”提供物理或虚拟化资源、甚至提供基础服务的逻辑层。现有的计算系统,被人为地分为基础设施层(IaaS),平台层(PaaS),软件层(SaaS),最上层就是应用层。鉴于此,Intel也把自己的DPU称之为“IPU”。
从优化技术的侧重点来看,越基础层的组件越倾向于以性能优先为导向,存在更多的“机器依赖”;越上层的优化越以生产效率为导向,通过层层封装,屏蔽底层差异,对用户透明。
为什么会有面向基础设施层的DPU?难道是说现有的数据中心的CPU、GPU、路由器、交换机,不能继续作为“面向基础设施层的数据处理单元”了吗?
在计算系统的研究,很大程度上是“优化”的研究;现有的基础设施不是不能,而是不够“优化”。如果没有新技术的发明和引入,最终需求和供给之间的矛盾就会越来越突出。
DPU的出现首先要解决的就是网络数据包处理的问题。随着核心网、汇聚网朝着100G、200G发展,接入网也达到50G、100G时,CPU无法提供足够的算力来处理数据包了。而且,网络带宽的增速来自于应用的丰富、数据中心规模的扩大、数字化进展的驱动,而 CPU 性能增速却随着摩尔定律的放缓而下降,这进一步加剧了服务器节点上CPU的计算负担。
另外一个例子是云计算场景下的“虚拟机之间的数据转发”问题,即OVS。通常,20个虚拟机需要消耗大概至强多核处理器5个核的算力,这是一笔比较大的开销,同时也是可用DPU的一个原因。
此外,目前的系统结构并不是为处理网络数据而生的,在高带宽网络、随机访问、高并发度收发的场景下效率并不高。现有技术开辟了用“轮询”替代中断来处理IO操作的方法,但这些在现有体系基础上的“修修补补”只能当做权宜之计,本质上是经典技术在新场景下的不适应。
有人把DPU单纯的理解为给CPU“减负”,把DPU作为一个网卡的“变种”,将其视为一个单纯的算法硬件化的载体,以“头脑简单,四肢发达”的形象示人。但如果我们重新审视一下系统功能的载体分布情况,就会看到DPU并非是一个单纯的加速 器,而是与CPU全方位配合的一个关键组件。
从主机负责所有的管理、控制、数据面的功能,到逐步“卸载”这些功能分别迭代出异构计算、智能网卡、DPU,DPU的价值愈发彰显,人们甚至可以以DPU为中心来构建计算系统。前不久,阿里云公布的CIPU宣称替代CPU成为新一代云计算核心硬件,可以说是把DPU推向了舞台中心,虽然尚有争议,但这也许正是DPU发展的方向。

02DPU与CPU、GPU的关系
从SmartNIC变为DPU并非简单的改改名字。为了在数据中心充分实现应用程序的效率,传输卸载、可编程的数据平面以及用于虚拟交换的硬件卸载等功能是SmartNIC的重要部分,但只是DPU的最基本要求之一。
要将SmartNIC提升到DPU的高度,还需要支持更多的功能,比如能够运行控制平面,以及在Linux环境下提供C语言编程等。
DPU是面向数据中心的专用处理器,新增了AI、安全、存储和网络等各种加速功能,将成为新一代的重要算力芯片。它能够完成性能敏感且通用的工作任务加速,更好地支撑CPU、GPU的上层业务,成为整个网络的中心节点。
老黄总结了3个DPU的特点:卸载、加速、隔离。对应DPU的三个主要应用场景:网络、存储、安全:
卸载:数据中心网络服务,比如虚拟交换、虚拟路由;数据中心存储服务,比如RDMA、NVMe(可以把它们理解成一些远程存储技术);数据中心的安全服务,比如防火墙、加解密等等
加速:上面说的那些服务和应用通常使用软件实现,并在CPU里运行。而DPU可以使用硬件实现并运行这些应用,这样比软件运行要快好几个数量级,这也就是我们常常会听到的“硬件加速”
隔离:由于上面说的应用在DPU里运行,而用户应用在CPU里运行,这样就把二者隔离开了。这样会带来很多安全和性能上的好处
一些基本的定位分析:
独立的DPU定位在基础设施处理器,主要是硬件加速
独立的GPU主要做应用层的弹性计算加速
而CPU主要负责低计算密度高价值密度的应用层的工作
如下图所示:CPU有60个面积单位,共计60个CPU核;GPU有60个面积单位,共计60个GPU Core(差不多对应流式多核处理器SM);而DPU则由10个CPU核、10个GPU核以及40个其他加速引擎核组成。
CPU是整个IT生态的定义者,无论是服务器端的x86还是移动端的ARM,都各自是构建了稳固的生态系统,不仅形成技术生态圈,还形成了闭合价值链。
GPU是执行规则计算的主力芯片,如图形渲染。经过NVIDIA对通用GPU (GPGPU)和CUDA编程框架的推广,GPU在数据并行的任务如图形图像、深度学习、矩阵运算等方面成为了主力算力引擎,并且成为了高性能计算最重要的辅助计算单元。2021年6月公布的Top500高性能计算机(超级计算机)的前10 名中,有六台(第2、3、5、6、8、9名)都部署有NVIDIA的GPU。
DPU的出现是异构计算的一个阶段性标志。与GPU的发展类似,DPU是应用驱动的体系 结构设计的又一典型案例;但与GPU不同的是,DPU面向的应用更加底层。随着DPU将数据中心的基础设施操作从CPU上卸载过来,数据中心将形成DPU、GPU、CPU三位一体的状态。
DPU首先作为计算卸载的引擎,直接效果是给CPU“减负”。DPU的部分功能可以在早期的TOE(TCP/IP Offloading Engine)中看到。正如其名,TOE就是将CPU的处理TCP协议的任务“卸载”到网卡上。
传统的TCP软件处理方式虽然层次清晰,但也逐渐成为网络带宽和延迟的瓶颈。软件处理方式对CPU的占用,也影响了CPU处理其他应用的性能。TCP卸载引擎(TOE)技术,通过将TCP协议和IP协议的处理进程交由网络接口控制器进行处理,在利用硬件加 速为网络时延和带宽带来提升的同时,显著降低了 CPU 处理协议的压力。
网络数据处理结构分析:
03DPU“降本增效”实力如何?
为了抢占DPU赛道的红利,如今国内涌现出越来越多初创企业,通过高起点的架构理念和自主创新研发,不少本土DPU初创公司已日益在这条百亿美元赛道上崭露头角。
目前来看,国内DPU赛道主流玩家包括芯启源、中科驭数、云豹智能、大禹智芯、边缘智芯、星云智联、云脉芯联等初创公司。
但在DPU技术路线上,各家选择略有不同。据笔者了解,从当前的主流技术架构来看,DPU的设计架构一般有三种,一是Arm多核或MIPS多核;第二种是基于FPGA的SmartNIC架构;第三种是异构核阵列的架构。
其中,基于Arm多核或MIPS多核阵列的架构虽然可以卸载明确定义的任务,例如标准化的安全和存储协议,但由于是基于软件可编程处理器,缺乏处理器并行性,这些处理器在用于网络处理时速度较慢。同时,多核SmartNIC ASIC中的固定功能引擎无法扩展来处理新的加密或安全算法,因为它们缺乏足够的可编程性,只能适应轻微的算法更改。
而基于FPGA的SmartNIC架构打造的DPU,具备灵活性高,可编程的优势。在开发上,可以如CPU一样具有高度的可编程性,也可以像在SoC解决方案上一样快速开发新功能,同时可以在接口上省去一些功夫 ,但很多重要的部分尚未突破,同时FPGA价格昂贵众所周知,借此打造的DPU方案成本也相对不菲。
相比之下,异构核阵列的架构目前最受初创公司看好,主要是由于异构具有更高的灵活性,并能带来更高效的数据处理效率。但也存在弱势,比如企业需要自研架构,研发投入成本较高。如KPU架构,将四类异构核组织起来,分别处理网络协议,OLAP\OLTP处理,机器学习和安全加密运算核。
但对于东数西算下的“大算力网络”应用来说,最终考量的依旧还是DPU的性价比。如今,随着东数西算项目的启动,国内以运营商为代表的云服务企业们对该领域的投入和重视度便持续提升,从3家运营商披露的资本开支规划来看,均在东数西算项目上耗资不菲。
从具体数据方面来看,中国移动规划2022年算力网络资本开支480亿元,投产对外可用IDC机架达约45万架,累计投产云服务器超66万台;中国电信2020年至2022年(预计)产业数字化占资本开支的比例或由15.6%上升至30%,其中2022年计划IDC投入65亿元(增加4.5万机架),算力投入140亿元(增加16万云服务器),2022年算力规模达3.8EFLOPS,同比增长超80%。
与此同时,中国联通也将围绕国家东数西算8大算力枢纽节点,优化扩大“5+4+31+x”的资源布局,比如中国联通在津启动“东数西算”京津冀国家枢纽节点建设项目,建成后可容纳机柜约2.5万架。中国联通贵安云数据中心项目总投资约60亿元,规划总机架3.2万架,可容纳60万台服务器。
有行业人士对笔者表示:“一台服务器可能没有GPU,但一定会有一颗或者多颗DPU,就好比每台服务器都必须配网卡类似。”以三大运营商中服务器投建体量最大的中国移动为例,2022年新增云服务器超66万台,每颗DPU若以1万元左右来计算,最低配置的话,运营商的附加成本支出将达到66亿元。
虽然前期对于投建数据中心项目而言,这种附加成本相对偏高,但DPU对整个数据中心系统的数据资源优化价值是长期且持续性的。据笔者从DPU芯片开发商处获悉,若按不同类型的云服务场景来划分,大规模采用DPU之后,数据中心的整体运营成本可降低约15%-30%左右,这对于动辄高达百万台机架规模的“东数西算”项目而言,成本的优化蔚为大观。
04 2025年是大规模入场期
众所周知,由于“东数西算”属于涉及信息安全的项目,这种特性决定了这场国家级的大工程注定会是国产DPU品牌的天下。当前,除了以阿里(目前多为自用)和华为等少数具备资本和产品落地实力的巨头之外,对于国内大多数DPU创企而言,眼下正处赛道征伐的“准备期”。
有行业人士告诉笔者,从2022年开始算起,DPU要真正在“东数西算”这类市场发挥作用,至少还需要2-3年的时间。即DPU市场真正的成熟期预计在2025年左右,届时只有硬件和软件同步成熟之后,才会真正开始在各类应用场景大规模爆发。
由于各家公司的DPU从今年开始着手设计开发,从设计到真正硬件系统成型至少也需要2-3年时间。近三年,各家初创企业之间并不会出现强烈的竞争关系,企业竞争的核心还是比拼技术迭代周期,产品导入市场的周期,以及小规模出货能力。
但要真正进入“东数西算”领域,即便是国内DPU企业也存在诸多门槛。当前,国内虽涉及“东数西算”的数据中心建设体量足以容纳一大波本土初创公司。但由于政府项目的特殊性,对企业在项目上的耕耘经验、DPU产品综合技术能力、产品性能及功能、配套能力、团队综合实力等方面都提出了多方考验。
另外,在关乎能耗的问题上,也逐渐成为DPU企业当前面临的主要痛点。能耗,对于任何一款芯片来说无疑都是很大的掣肘,DPU也不例外。尤其是随着2021年下半年监管开始更为严厉的把控,以东部沿海区域为主,政府针对数据中心项目的管理办法越来越严格,管理路径和手段也逐渐增多。
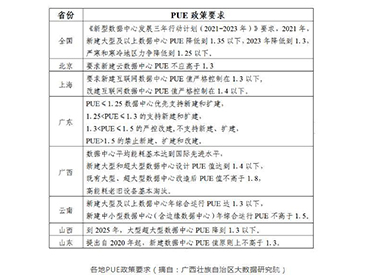
而数据中心项目作为重点用能单位,需要地方政府审批并提供节能报告等,提供的各项指标也由各地发改和经信相关部门设置和管理。针对数据中心的指标以控制能耗为主,主要包括PUE(Power Usage Effectiveness,电能利用效率),可再生能源结构比例以及碳排放量三个维度,其中PUE是核心的政策抓手。
据悉,PUE是数据中心总能耗与IT设备能耗的比值,基准是2,数值越接近1代表其用能效率越高。2021年7月,工信部发布《新型数据中心发展三年行动计划(2021-2023年)》指出,能效水平方面,新建大型及以上数据中心PUE降低到1.3以下,严寒和寒冷地区力争降低到1.25以下。从各地情况来看,2021年上海要求存量数据中心PUE不高于1.4,新建数据中心PUE限制在1.3以下,北京和深圳要求PUE在1.4以下。
但2022年至今,不到一年时间内,各地指标从1.5降至1.4,个别寒冷地区甚至控制到1.25。可实际上,1.3以下的数值对一个规模型的数据中心来说很难达到,这也对数据中心采用的各种零部件提出了更高的能耗要求。
不过,由于技术的发展不够成熟,当前“过热”、功耗太高是DPU相当大的痛点。即便是国外的Fungible、英伟达的DPU,还是英特尔的IPU,功耗都是此类产品的一大瑕疵。过去,单颗网络DMA芯片功耗仅5瓦左右,如今一个DPU功耗动辄100瓦以上(Fungible F1 120瓦)。
因此,目前来说,大部分应用场景尚且很难承受如此大功耗的网络设备。尤其是在100/200G以上,在光模块功耗已经超过网络设备的情况下,如果再增加一个100瓦的网络DPU,将会极大的提升网络的能源消耗,更难符合当前“东数西算”越来越严格的PUE要求。由此可见,DPU入局“东数西算”场景,功耗仍旧是当前的痛点所在。
扫二维码用手机看
相关新闻




